Maximum Likelihood và Maximum A Posteriori
Phần này mình tìm hiểu 2 cách ước lượng tham số thường được dùng trong các mô hình machine learning thống kê.
1. Giới thiệu
- Có rất nhiều mô hình machine learning được xây dựng dựa trên các mô hình thống kê.
- Ký hiệu θ là tập hợp tất cả các tham số của mô hình đó.
- Learning là quá trình estimate bộ tham số θ sao cho mô hình tìm được khớp với phân phối của dữ liệu nhất.
| Maximum Likelihood estimation(ML estimation) - MLE | Maximum A Posteriori estimation(MAP estimation) - MAP |
|---|
| - Dựa trên dữ liệu đã biết trong tập training. | - + những thông tin có được bằng cảm quan của người xây dựng mô hình, cảm quan càng rõ ràng, càng hợp lý thì khả năng thu được bộ tham số tốt càng cao. |
2. Maximum Likelihood estimation(ML estimation) - MLE
Giả sử có các điểm dữ liệu x1,x2,...,xN. Giả sử thêm rằng ta đã biết các điểm dữ liệu này tuân theo một phân phối nào đó được mô tả bởi bộ tham số θ.
MLE là việc đi tìm bộ tham số θ sao cho xác suất sau đây đạt giá trị lớn nhất:
θ=θmaxp(x1,...xN∣θ)
2.1. Log-likelihook
Việc giải bài trực tiếp bài toán đi tìm mô hình xác suất đồng thời cho toàn bộ dữ liệu là ít khả thi nên ta sẽ tiếp cận bằng cách tìm xấp xỉ likelihood(giả sử rằng các điểm dữ liệu xn là độc lập với nhau):
p(x1,...xN∣θ)≈n=1∏Np(xn∣θ)
Việc tối ưu một tích thường phức tạp hơn việc tối ưu một tổng nên ta chuyển về dạng sau:
θ=θmaxn=1∑Nlog(p(xn)∣θ)
* log của một tích bằng tổng các log và vì log là một hàm đồng biến, một biểu thức dương sẽ là lớn nhất nếu log của nó là lớn nhất và ngược lại.
Ví dụ: Xem thêm ở đây
3. Maximum A Posteriori estimation(MAP estimation) - MAP
Khi tập training nhỏ thì việc ước lượng theo MLE là không đáng tin và nhiều khả năng đã bị overfitting. MAP ra đời nhằm giải quyết vấn đề này.
Trong MAP, ta giới thiệu một giả thiết biết trước được gọi là prior của tham số θ, ta có hàm mục tiêu như sau:
θ=argθmaxp(θ∣x1,…,xN)
Định lý Bayes
P(A∣B)=P(B)P(B∣A)P(A)=normalizing_constantlikelihood∗prior
Áp dụng vào công thức trên ta được
θ=argθmax[p(x1,…,xN)p(x1,…,xN∣θ)p(θ)]=argθmax[p(x1,…,xN∣θ)p(θ)]=argθmax[i=1∏Np(xi∣θ)p(θ)]
Như vậy, điểm khác biệt lớn nhất giữa hai bài toán tối ưu MLE và MAP là việc hàm mục tiêu của MAP có thêm p(θ)l, tức phân phối của θ. Phân phối này chính là những thông tin ta biết trước về θ và được gọi là prior.
4. Áp dụng cho bài toán tung đồng xu
Tung đồng xu N lần có n lần nhận được mặt head và m=N−n lần nhận được mặt tail.
4.1. Sử dụng MLE
Vì đây là một xác suất của biến ngẫu nhiên nhị phân rời rạc, ta có thể nhận thấy việc nhận được mặt head hay tail khi tung đồng xu tuân theo phân phối Bernoulli:
p(xi∣λ)=λxi(1−λ)1−xi
Khi đó tham số mô hình λ có thể được ước lượng bằng việc giải bài toán tối ưu sau:
λ=argλmax[p(x1,x2,…,xN∣λ)]=argλmax[i=1∏Np(xi∣λ)]=argλmax[i=1∏Nλxi(1−λ)1−xi]=argλmax[λ∑i=1Nxi(1−λ)N−∑i=1Nxi]=argλmax[λn(1−λ)m]=argλmax[nlog(λ)+mlog(1−λ)]
Tới đây, bài toán tối ưu có thể được giải bằng cách lấy đạo hàm của hàm mục tiêu bằng 0. Tức λ là nghiệm của phương trình
λn−1−λm=0⟺λn=1−λm⟺λ=n+mn=Nn
4.2. Sử dụng MAP
Nhận thấy rằng phân phối Beta có cùng họ với phân phối Bernoulli. Ta sẽ sử dụng MAP với prior là một Beta[α,β], được gọi là siêu tham số (hyperparameters).
Tối ưu MAP:
λ=argλmax[p(x1,…,xN∣λ)]=argλmax[(i=1∏Nλxi(1−λ)1−xi)λα−1(1−λ)β−1]=argλmax[(λ∑i=1Nxi+α−1)(1−λ)(N−∑i=1Nxi+β−1)]=argλmax[λn+α−1(1−λ)m+β−1]
Tương tự như MLE thì ta lấy log và lấy đạo hàm của hàm mục tiêu, ta được nghiệm:
λ=N+α+β−2n+α−1
Việc còn lại là chọn α và β
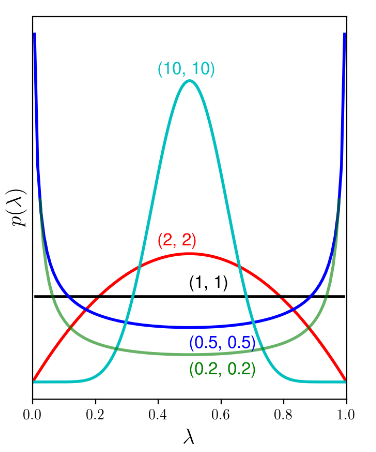
Nếu ta chọn α=β=1, ta nhận được phân phối đều vì đồ thị hàm mật độ xác suất là một
đường thẳng. Lúc này, xác suất của λ tại mọi vị trí trong khoảng [0, 1] là như nhau và thay vào công thức trên ta được λ=n/N
Nếu chọn α=β=2 ta sẽ thu được λ=N+2n+1. Chẳng hạn khi N=5 và n=1 như trong hình. MLE cho kết quả λ=1/5, MAP sẽ cho kết quả λ=2/7, gần với 1/2 hơn.
5. MAP giúp tránh overfitting
Việc chọn các hyperparameter thường được dựa trên thực nghiệm, chẳng hạn bằng cross-
validation. Việc thử nhiều bộ tham số rồi chọn ra bộ tốt nhất là việc mà các kỹ sư machine
learning thường xuyên phải đối mặt. Cũng giống như việc chọn regularization parameter để
tránh overfitting vậy.
Nếu viết lại bài toán MAP dưới dạng:
θ=argθmaxp(X∣θ)p(θ)=argθmax[logp(X∣θ)+logp(θ)]
Ta có thể thấy rằng hàm mục tiêu có dạng L(θ)+λR(θ) giống như trong regularization, với hàm log-likelihood đóng vai trò như hàm mất mát L(θ), và log của prior đóng vai trò như hàm λR(θ). Ta có thể nói rằng, MAP chính là một phương pháp giúp tránh overfitting trong các mô hình machine learning thống kê.