Union Find
Trong khoa học máy tính, có rất nhiều bài toán yêu cầu kiểm tra xem hai phần tử có thuộc cùng một nhóm hay không. Chẳng hạn, trong một mạng xã hội, ta muốn biết hai người dùng có kết nối gián tiếp thông qua bạn bè hay không. Trong một mạng máy tính, nếu hai máy tính có kết nối gián tiếp thông qua nhiều bước, ta muốn biết chúng có thuộc cùng mạng hay không,.... Những bài toán này đều có chung một yêu cầu: quản lý và truy vấn các nhóm phần tử được hợp nhất theo thời gian.
Để giải quyết bài toán này một cách hiệu quả, Union-Find (hay còn gọi là Disjoint Set Union - DSU) là một trong những cấu trúc dữ liệu mạnh mẽ nhất. Với các kỹ thuật tối ưu như Union by Rank và Path Compression, Union-Find giúp thực hiện các thao tác hợp nhất (union) và tìm kiếm (find) với độ phức tạp gần như .
Trong bài viết này, chúng ta sẽ cùng tìm hiểu về Union-Find từ cơ bản đến nâng cao, bao gồm các cách triển khai, cải tiến và ứng dụng thực tế của nó.
1. Đặt bài toán (Model the problem)
Cho một tập hợp N objects, mỗi object có thể được đại diện bởi một số nguyên từ 0 đến N-1. Chúng ta có thể thực hiện các thao tác sau:
- Union(p, q): Kết nối object p và object q.
- Connected(p, q): Kiểm tra xem object p và object q có kết nối với nhau không.
Ví dụ:

union(4, 3);
union(3, 8);
union(6, 5);
union(9, 4);
union(2, 1);
connected(0, 7); // false
connected(8, 9); // true
union(5, 0);
union(7, 2);
union(6, 1);
union(1, 0);
connected(0, 7); // true
Ta cần implement 2 hàm:
- Find query: Kiểm tra xem 2 objects có cùng components hay không.
- Union command: Kết hợp 2 components chứa 2 objects đó thành 1 component chung.
Mục tiêu:
- Thiết kế một data structure hiệu quả cho bài toán
- Số lượng objects N có thể rất lớn
- Số lượng lệnh union M có thể rất lớn
- Có thể dùng
Find queryvàUnion commandxen kẽ nhau
2. Quick find (hướng tiếp cận trực quan mà nghĩ ngay đến)
Ta vẫn tuân theo các bước để phát triển một thuật toán được giới thiệu ở phần intro. Sau khi xác định rõ được vấn đề cần giải quyết thì ta sẽ tìm tìm giải pháp tức thời để giải quyết vấn đề và sau đấy đánh giá và cải thiện dần.
2.1. Data structure
- Sử dụng một
integer arrayid[]có độ dài là N. - Ta sẽ có
pvàqkết nối khi chúng có cùngid.

2.2. Giải thuật
- Find: Kiểm tra xem
pvàqcó cùngid. - Union: Để kết hợp 2 components chứa
pvàqthì ta sẽ thay đổi tất cả các entries cóidtrùng vớiidcủapsangidcủaq.
2.3. Implementation
class QuickFind {
private:
int id[10];
public:
QuickFind() {
for (int i = 0; i < 10; i++) {
id[i] = i;
}
}
bool connected(int p, int q) { return id[p] == id[q]; }
void union_cmd(int p, int q) {
int pid = id[p];
int qid = id[q];
for (int i = 0; i < 10; i++) {
if (id[i] == pid) {
id[i] = qid;
}
}
};
};
2.4. Đánh giá
| Algorithm | initialize | union | find |
|---|---|---|---|
| QuickFind | N | N | 1 |
Nhận thấy rằng thuật toán này không quá hiệu quả vì nó mất tới để thực hiện N lệnh union trên N objects.
3. Quick Union
3.1. Data structure
- Sử dụng một
integer arrayid[]có độ dài là N. id[i]là parent củai.root(i)làid[id[id[...id[i]...]]]cho đến khii == id[i].

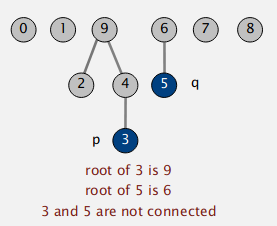
3.2. Giải thuật
- Find: Kiểm tra xem
pvàqcó cùngroot. - Union: Để kết hợp 2 components chứa
pvàqthì ta sẽ thay đổirootcủapthànhrootcủaq.
Với ví dụ trên sau khi thực hiện union(3, 5) ta sẽ được:

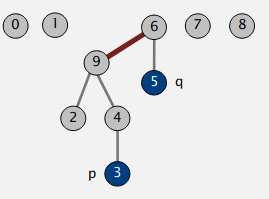
3.3. Implementation
class QuickUnion {
private:
int id[10];
int root(int i) {
while (i != id[i]) {
i = id[i];
}
return i;
}
public:
QuickFind() {
for (int i = 0; i < 10; i++) {
id[i] = i;
}
}
bool connected(int p, int q) { return root(p) == root(q); }
void union_cmd(int p, int q) {
int i = root(p);
int j = root(q);
id[i] = j;
};
};
3.4. Đánh giá
| Algorithm | initialize | union | find |
|---|---|---|---|
| QuickFind | N | N | 1 |
| QuickUnion | N | N+(bao gồm cost tìm root) | N |
-
Hạn chế của QuickFind:
- Union cost quá cao.
-
Hạn chế của QuickUnion:
- Find cost quá cao.
- Trees có thể trở nên quá sâu.
4. Cải thiện
4.1. Weighted Quick Union
Ta sẽ cải thiện thuật toán Quick Union bằng cách đảm bảo rằng cây sẽ không quá sâu. Để làm được điều này, ta sẽ luôn kết hợp cây nhỏ vào cây lớn hơn.
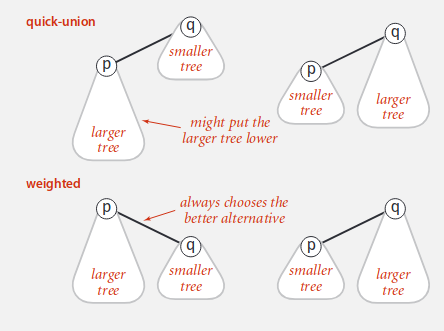
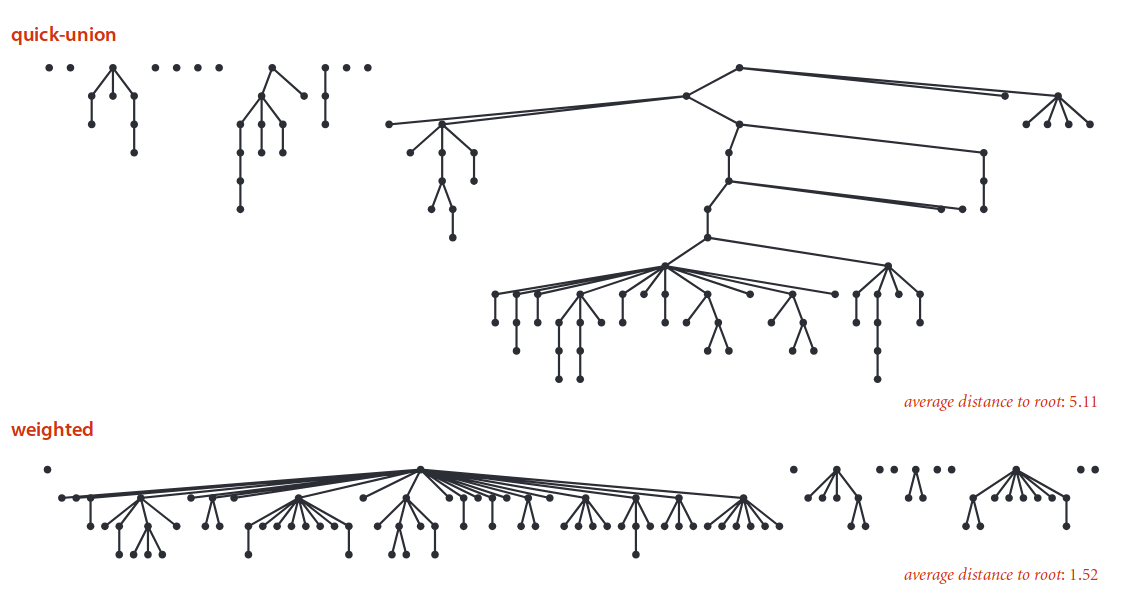
Ta có thể thấy rằng việc sắp xếp cây theo kích thước giúp giảm chiều sâu của cây. Điều này giúp giảm độ phức tạp của find và union.
4.2. Giải thuật
-
Data structure: Tương tự như Quick Union, nhưng ta sẽ thêm một mảng
sz[]để lưu kích thước của cây. -
Find: Tương tự như Quick Union.
return root(p) == root(q); -
Union: Để kết hợp 2 components chứa
pvàqthì ta sẽ:- Nối
rootcủa cây nhỏ vàorootcủa cây lớn. - Update
sz[].
int i = root(p);
int j = root(q);
if (i == j) return;
if (sz[i] < sz[j]) { id[i] = j; sz[j] += sz[i]; }
else { id[j] = i; sz[i] += sz[j]; } - Nối
4.3. Đánh giá
| Algorithm | initialize | union | find |
|---|---|---|---|
| QuickFind | 1 | ||
| QuickUnion | |||
| Weighted QuickUnion |
- Find: Tùy thuộc vào chiều sâu của
pvàq. - Union: Sẽ là tức thì nếu biết
rootcủapvàq.
Ta nhận thấy rằng việc giảm chiều sâu của cây giúp giảm độ phức tạp của find và union.
Ta có cải tiến thứ 2: path compression.
4. Path Compression
4.1. Giải thuật
Sau khi thực hiện find ta sẽ cập nhật lại root của p và tất cả các root trên đường đi của p về root của p.
Version 1 (Two pass): Thêm một vòng lặp vào hàm root để cập nhật lại root của p và tất cả các root trên đường đi của p về root của p.
Version 2 (One pass): Thay vì thêm 1 vòng lặp vào hàm root. Trên đường tìm root của p, ta sẽ trỏ p về grand parent của nó.
4.2. Implementation
Two pass:
int root(int i) {
// First pass: Tìm root và lưu path
std::vector<int> path;
int current = i;
while (current != id[current]) {
path.push_back(current);
current = id[current];
}
int root = current;
// Second pass: Update các node trong path trỏ về root
for (int node : path) {
id[node] = root;
}
return root;
One pass:
int root(int i) {
while (i != id[i]) {
id[i] = id[id[i]];
i = id[i];
}
return i;
}
So sánh:
- One pass: Đơn giản hơn vì yêu cầu ít bộ nhớ hơn. Nó không hoàn toàn làm phẳng cây nhưng nó giảm độ sâu của cây đáng kể.
- Two pass: Làm phẳng cây hoàn toàn giúp việc tìm
rootở những lần sau gần như là . Tuy nhiên nó yêu cầu nhiều bộ nhớ hơn và cũng phức tạp hơn.
5. Ứng dụng
5.1. Percolation
Percolation là một mô hình thường được sử dụng trong khoa học máy tính và vật lý để mô phỏng quá trình "thấm" hoặc "lan truyền" qua một hệ thống. Hãy tưởng tượng một lưới vuông (grid) kích thước N×N, trong đó mỗi ô có thể ở trạng thái "mở" (open) hoặc "đóng" (blocked). Mục tiêu là kiểm tra xem liệu chất lỏng (hoặc tín hiệu) có thể "thấm" từ hàng trên cùng của lưới xuống hàng dưới cùng hay không khi các ô được mở ngẫu nhiên.
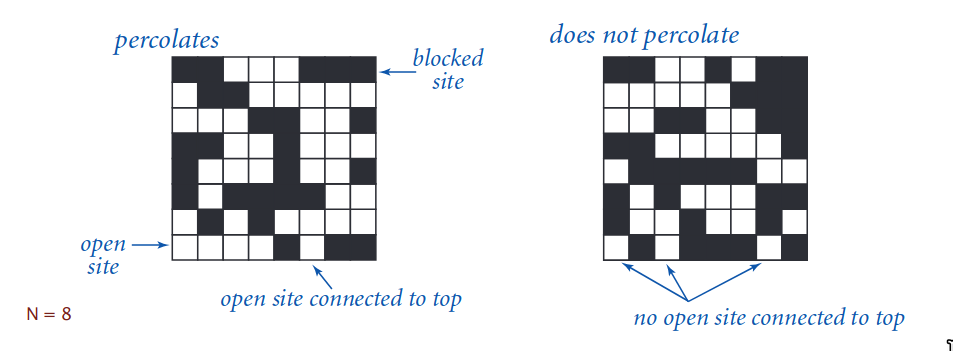
Qua mô tả bài toán ta có thể thiết lập được class Percolation cơ bản như sau:
class Percolation {
private:
int N; // Kích thước lưới NxN
vector<bool> openSites; // Trạng thái mở/đóng của các ô
public:
// Mở một ô tại (row, col)
void open(int row, int col) {
}
// Kiểm tra xem hệ thống có thấm không
bool percolates() {
}
}
Nhận thấy đây là bài toán về tính liên thông giữa các ô trên lưới. Ta có thể sử dụng Weighted Quick Union để giải quyết bài toán này.
class UnionFind {
private:
vector<int> parent;
vector<int> rank;
public:
UnionFind(int n) {
parent.resize(n);
rank.resize(n, 0);
for (int i = 0; i < n; i++) {
parent[i] = i;
}
}
int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
void union_cmd(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX == rootY) return;
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else {
parent[rootY] = rootX;
if (rank[rootX] == rank[rootY]) {
rank[rootX]++;
}
}
}
bool connected(int x, int y) {
return find(x) == find(y);
}
};
Áp dụng vào bài toán ta có:
class Percolation {
private:
int N;
vector<bool> openSites;
UnionFind uf;
int virtualTop;
int virtualBottom;
int xyTo1D(int row, int col) { return row * N + col; }
public:
Percolation(int n) : N(n), openSites(n * n, false), uf(n * n + 2) {
virtualTop = n * n;
virtualBottom = n * n + 1;
}
void open(int row, int col) {
if (row < 0 || row >= N || col < 0 || col >= N) {
cout << "Vi tri khong hop le!" << endl;
return;
}
int index = xyTo1D(row, col);
if (openSites[index])
return;
openSites[index] = true;
if (row == 0)
uf.union_cmd(index, virtualTop);
if (row == N - 1)
uf.union_cmd(index, virtualBottom);
int directions[4][2] = { {-1, 0}, {1, 0}, {0, -1}, {0, 1} };
for (auto &dir : directions) {
int newRow = row + dir[0];
int newCol = col + dir[1];
if (newRow >= 0 && newRow < N && newCol >= 0 && newCol < N) {
int neighborIndex = xyTo1D(newRow, newCol);
if (openSites[neighborIndex]) {
uf.union_cmd(index, neighborIndex);
}
}
}
}
bool percolates() { return uf.connected(virtualTop, virtualBottom); }
};
5.2. Social network connectivity
Cho một mạng xã hội gồm thành viên và log file chứa timestamps ghi lại thời điểm các cặp thành viên kết bạn, hãy thiết kế một thuật toán để xác định thời điểm sớm nhất khi tất cả các thành viên được kết nối (tức là mọi thành viên đều có thể kết bạn gián tiếp thông qua chuỗi bạn bè). Giả sử log file được sắp xếp theo thứ tự thời gian và quan hệ kết bạn là một quan hệ tương đương. Thuật toán của bạn nên có độ phức tạp thời gian là hoặc tốt hơn và sử dụng bộ nhớ phụ thuộc tuyến tính vào .
Phân tích bài toán
-
Input:
- : số members(nodes) trong mạng xã hội.
- : số timestamps trong log file(edges).
- log file: list gồm triples() thể hiện thời điểm thành viên và kết bạn.
-
Goal: Tìm thời điểm sớm nhất khi tất cả các members được kết nối.
Thuật toán
Union Find data structure
- Dùng một array
parentsize để lưu parent của mỗi thành viên. - Dùng một array
ranksize để lưu rank của mỗi thành viên. - Khởi tạo mỗi thành viên là một nhóm riêng biệt.
- Implement hàm
findđể tìm root. - Implement hàm
union_cmdđể merge các nhóm. - Track số nhóm, bắt đầu là .
Implementation
class UnionFind {
private:
vector<int> parent;
vector<int> rank;
int numComponents;
public:
UnionFind(int n) {
parent.resize(n);
rank.resize(n, 0);
numComponents = n;
for (int i = 0; i < n; i++) {
parent[i] = i;
};
}
int find(int x) {
if (parent[x] != x) {
parent[x] = find(parent[x]);
}
return parent[x];
}
void union_cmd(int x, int y) {
int rootX = find(x);
int rootY = find(y);
if (rootX != rootY) {
if (rank[rootX] < rank[rootY]) {
parent[rootX] = rootY;
} else if (rank[rootX] > rank[rootY]) {
parent[rootY] = rootX;
} else {
rank[rootY] = rootX;
rank[rootX]++;
}
numComponents--;
}
}
int getNumComponents() const { return numComponents; }
};
int earliestConnectionTime(int n, const vector<tuple<int, int, int>> &log) {
if (n <= 0)
return -1;
UnionFind uf(n);
for (const auto &entry : log) {
int timestamp = get<0>(entry);
int u = get<1>(entry);
int v = get<2>(entry);
if (u < 0 || u >= n || v < 0 || v >= n) {
continue;
}
uf.union_cmd(u, v);
if (uf.getNumComponents() == 1)
return timestamp;
}
return -1;
}
int main(int argc, char *argv[]) {
int n = 4;
vector<tuple<int, int, int>> log = { {1, 0, 1}, {2, 2, 3}, {3, 0, 3} };
int result = earliestConnectionTime(n, log);
if (result != -1) {
cout << "Earliest time all members are connected: " << result << endl;
} else {
cout << "All members never connected." << endl;
}
n = 3;
log = { {1, 0, 1} };
result = earliestConnectionTime(n, log);
if (result != -1) {
cout << "Earliest time all members are connected: " << result << endl;
} else {
cout << "All members never connected." << endl;
}
return 0;
}
Earliest time all members are connected: 3
All members never connected.